内容提要:中国民族语言的系属复杂,数量众多,方言差别显著,国内与国际学术界关于中国语言数量的统计结果十分悬殊。本文从微观和实证的角度描述了中国与国际组织关于中国语言谱系分类、身份识别和方言划分的不同标准,对标准的异同做了客观的分析和评价。认为国际组织采用的“语言群体认同”和“词汇相似度”(lexical similarity)标准与中国学界语言的“民族”族属和“同源词”标准之间,有一定的相通之处;然而在技术上,语言可懂度和语言认同度标准的可操作性不高,是《世界民族语言志》(Ethnologue)语言识别结果时常会受到诟病的主要问题。
关 键 词:语言分类;语言识别;语言可懂度;语言群体认同;分歧与成因
标题注释:本研究得到北京语言大学语言资源高精尖创新中心项目“语言识别理论及语言数量统计的方法论研究”(KYR17018)的资助。
作者简介:黄行,男,中国社会科学院民族学与人类学研究所研究员,主要研究方向为少数民族语言。
中国是世界上语言多样性最丰富的国家之一。中国语言的多样性不仅表现在语言谱系复杂,语种数量众多,并且语言(特别是汉藏语系语言)内部方言之间的相似度和可懂度也较一般意义上语言的方言变体更低,以致在中国同一语言的方言经常被国外学术界视为独立的语言。因此国内外关于中国语言数量的统计结果,存在着比世界上其他国家语言更大的差别。以权威中外文献关于中国语言数量的统计为例说明。(见表1)
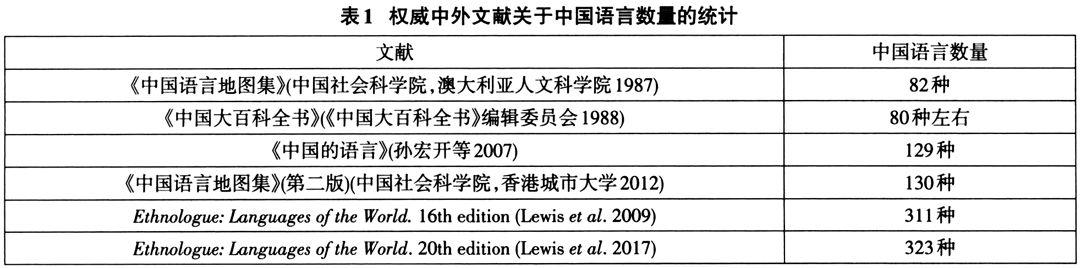
国内外学术界关于中国语言数量统计结果的差别是因为采用不同的语言识别标准所致。即国内民族语言学界比较注重:(1)民族对语言识别的作用。在中国,语言是构成民族的基本要素之一,反之民族也是语言识别的重要参数。(2)同源词对语言识别的作用。同一种语言的各方言之间一定要有相当比例的同源词;将属于历史语言学范畴的同源词用于共时方言划分,是借鉴于汉语方言依据古代汉语音韵特征进行方言分区的方法。(3)语言结构类型标准。即属于同一种语言的各方言之间要有结构类型的相似性。(黄行2009)国外学界通常强调语言和方言的区别在于:(1)通话的可懂度(intelligibility)。语言内方言要有较高的可懂度,否则应该是独立的语言。(2)说话人对民族语言群体(ethnolinguistic group)的认同度。如两种话之间有较高的可懂度,但是语言使用者并不认同为相同的语言,也应看作不同的语言。
国际组织(如联合国教科文组织和国际标准化组织)公布的世界语言共有约7000种,主要是依据世界少数民族语文研究院(SIL International)编纂并每5年修订一次的Ethnologue:Languages of the World(本文译作《世界民族语言志》)一书所基于语言可懂度和认同度标准的识别结果和统计数据。该书最新的2017年第20版共收录世界7099种语言(Lewis et al.2017),其中中国大陆收录了299种,加上中国台湾收录的25种(多数为台湾南岛语系语言,也包括与大陆相同的汉语官话、闽南话和客家话,不同国家或地区的同一语言不会重复统计在语言总数之内)、中国香港7种(大陆没有的是英语和属于克里奥尔语的澳门土语Macanese)、中国澳门6种(大陆没有的是葡萄牙语和澳门土语)。合计中国不重复的语言有323种(占世界语言总数的4.5%),其数量是国内学界认定的中国语言的两倍多。
客观地讲,上述文献对包括中国语言在内的世界语言身份识别与统计结果,已经形成一定学术认知度和国际标准的影响,因此本文拟从微观和实证的角度对中国与上述国际组织关于中国语言的谱系分类、身份识别和方言划分的差别做一客观的分析和评价。采用的中国民族语言数据主要来自《中国大百科全书》(2011)、《辞海》(2009)、《中国少数民族语言简志丛书》(修订本)(2009)、《中国新发现语言研究丛书》(1998-)、《中国的语言》(2007)和《中国语言地图集》(第二版)(2012)等权威文献。
二、语言谱系分类
中国学界采用的中国语言谱系分类基本仍为汉藏、阿尔泰、南亚、南岛、印欧五大语系及其以下各分若干语族语支的体系(《中国大百科全书》等)。
《世界民族语言志》关于中国语言的谱系分类和分布与中国区别不大,但是语言系属的层级差别很大,主要是取消了一些有争议的语系,将下位的语族升级为语系、语支升级为语族,甚至一些语言(如苗语、彝语)的方言升级为包含许多语言的语支,还有的方言甚至次方言土语升级为独立的语言。具体分类情况为:
汉藏语系仅包括汉语(Chinese)和藏缅语族(Tibeto-Burman),藏缅语族的层级极其复杂,语言数量也甚多,共含441种语言,但多未分布在中国。
侗台语族升级为“台-卡岱语系”(Tai-Kadai),其下再分侗台语族[Kam-Tai,含侗水(Kam-Sui)、台(Tai)、拉珈(Lakkia)语支],黎语族[Hlai,含黎(Hlai)和加茂(Jiamao)语支],卡拉语族(Kra,含中部、东部和西部语支,所谓“仡央语支”诸语言即包含于卡拉语族各语支)。
苗瑶语族升级为“苗瑶语系”(Hmong-Mien),分苗语族[Hmong,含黔东(Qiandong)、湘西(Xiangxi)、川黔滇(Chuanqiandian)、布努(Bunu)、巴哼(Pa-hng)等语支]、畲语族(Ho Nte)和瑶语族[Mien,含标交(Biao-Jiao)、勉金(MianJin)、藻敏(Zaomin)等语支]。
阿尔泰语系未设,其下的三个语族分别升级为语系:
突厥语系(Turkic),大多数语言分布在中亚和西亚,中国的突厥语系语言分属东部、北部、南部语组;
蒙古语系(Mongolic),包括中国在内的大多数蒙古语系语言都属东部语组,西部语组仅指阿富汗的莫戈勒语(Mogholi);
通古斯语系(Tungusic),分北部和南部两个语组,中国的满语支语言(含满语和锡伯语)属南部语组,通古斯语支语言(含鄂温克语、鄂伦春语和赫哲语)属北部语组。
表2为中国语言两种分类体系对照的一览表。
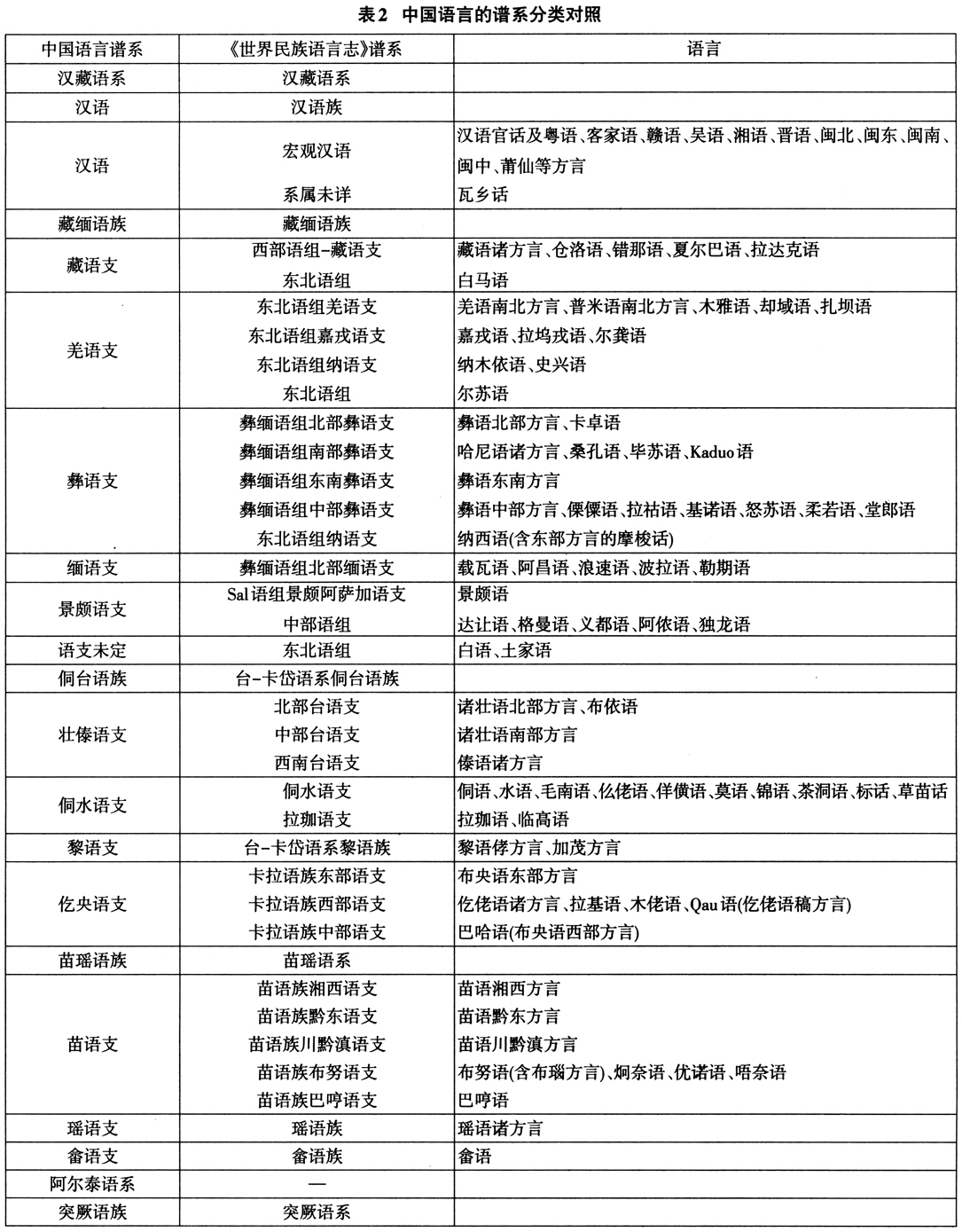
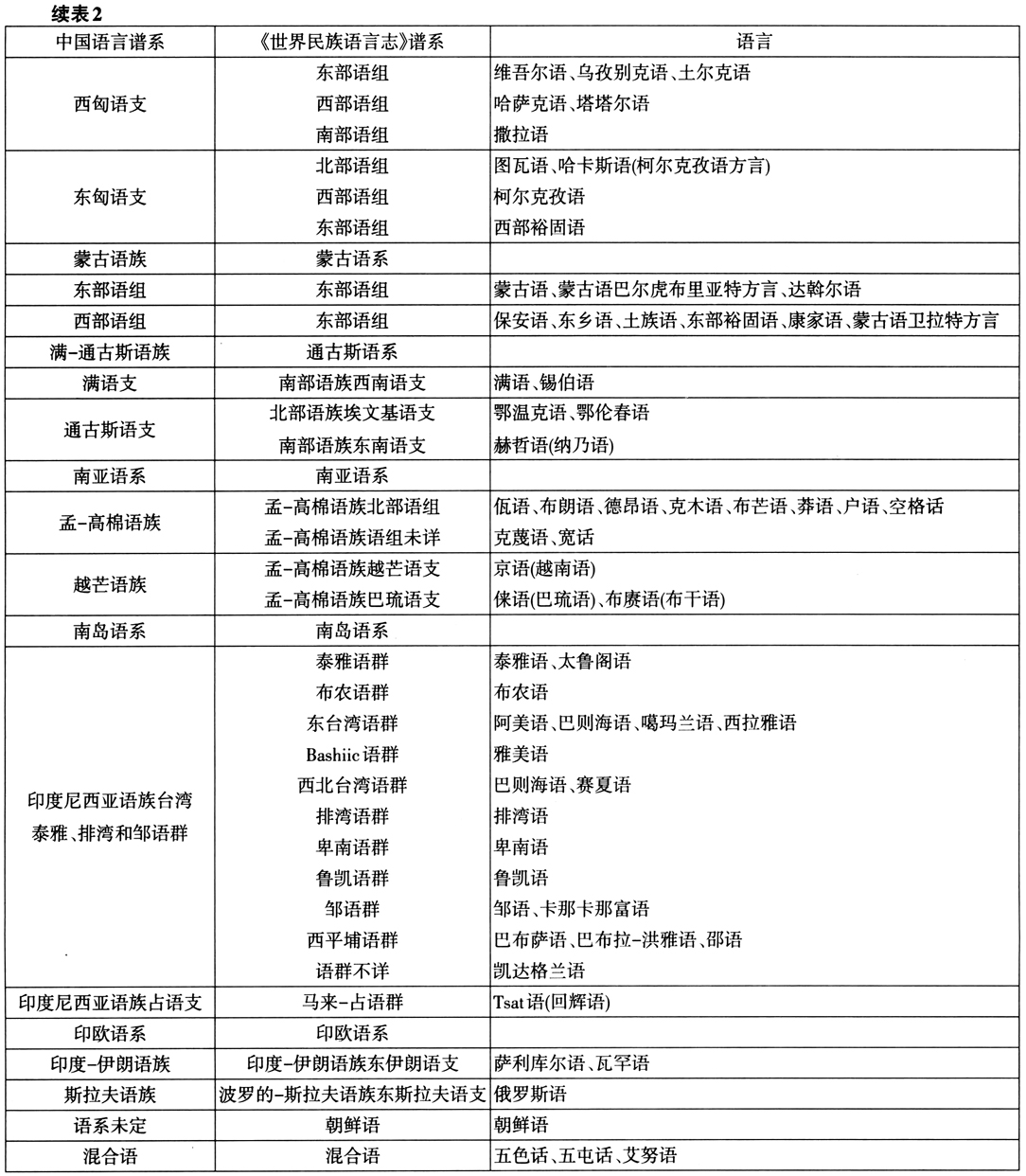
中国的语言在语系层面争议较大,两个所谓最大的语系——汉藏语系和阿尔泰语系都仍仅是某种假说,国际语言学界基本已不采用这样的分类法。例如《不列颠百科全书》(网络版)中的汉藏语系仅包括汉语和藏缅语族,苗瑶语倾向于系属未定,或独立的苗瑶语系(Hmong-Mien family);“侗台语”倾向于为“台-卡岱语系(TaiKadai family),侗台语和汉语语音系统(特别是声调)之间的相似性不再被视为同源的证据。关于阿尔泰语系的突厥语族、蒙古语族和满-通古斯语族语言,在词汇、形态、句法结构以及某些语音学特征方面表现出显著的相似性,但是不能证明它们具有遗传学的亲属关系。①影响较为广泛的维基百科的中国语言系属分类与《世界民族语言志》完全一致②,不再赘述。
以汉藏语系为例,曾经被认为语系成立的证据,即:(1)形成声调系统的趋向(是语言共同起源最有力的证据);(2)单音节趋向;(3)浊音普遍清化;(4)共同的词汇。(李方桂1973/1980)前3项主要表现在与汉藏语无明显发生学关系的侗台语和苗瑶语中,而与汉语有大量确凿同源词的诸藏缅语皆不具备这3项特征,因此所谓汉藏语系共有特征实际是东亚地区比较普遍的区域共性或语言联盟(sprachbund)现象。同理,阿尔泰语系语言构词与构形的黏着类型、SOV语序和元音和谐律等共有特征,学界也倾向于是语言接触形成的区域性现象。因此《世界民族语言志》采取仅包括汉语和藏缅语族的“汉藏语系”“台-卡岱语系”与“苗瑶语系”,以及用“突厥语系”“蒙古语系”“通古斯语系”取代传统的“阿尔泰语系”的分类格局,是当前国际上比较普遍的语言谱系分类体系。
再看汉藏语系语言“共同的词汇”证据。传统上包括侗台语和苗瑶语的汉藏语系分类比较强调语系内部语族之间存在许多共同的词汇,随着新语料的公布及实证性研究的不断深入,这些“共同词汇”的词源也日益显明。下面以侗台语和苗瑶语最常用的一些身体器官词为例说明,这些核心词语多与汉藏语无关,却能与南岛语普遍对应。(见表3)
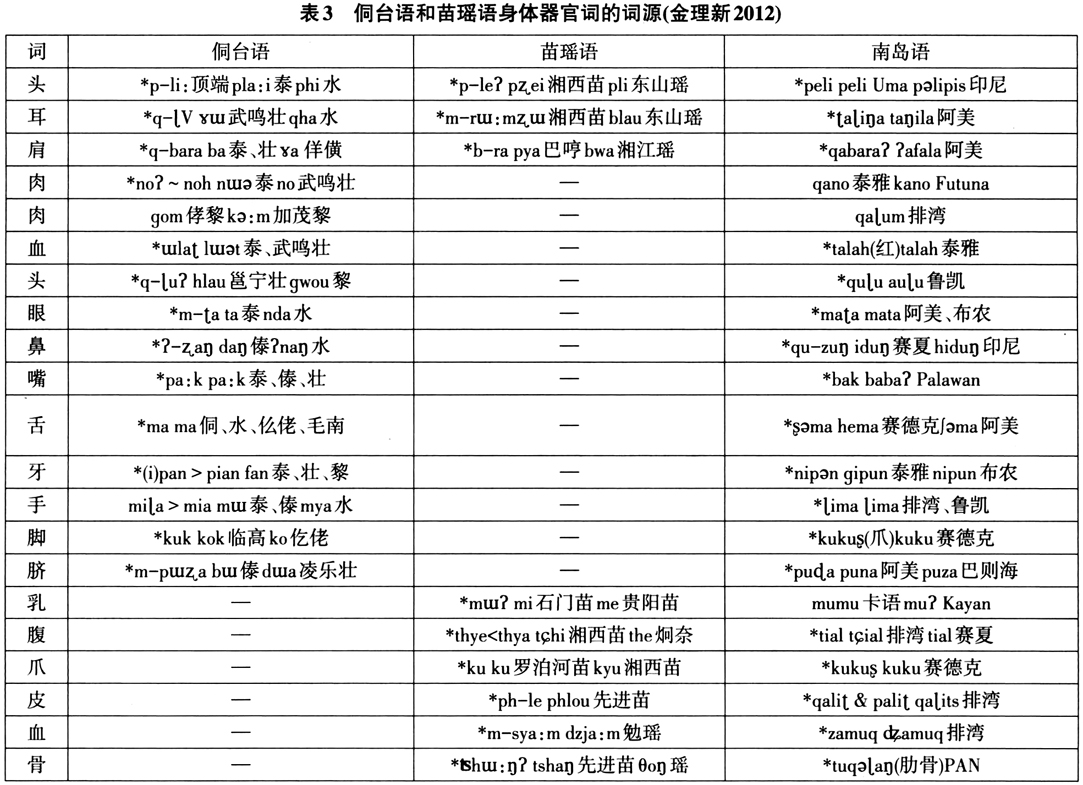
因此关于侗台语和苗瑶语的系属问题,《不列颠百科全书》专门提到美国语言学家白保罗(Paul K.Benedict)将侗台语和苗瑶语与南岛语联系起来的澳泰语系(Austro-Tai),尽管这一联系在学界尚未形成成熟的共识。
三、语言身份识别
中国语言身份的识别标准较宽,许多在中国被认为是方言甚至次方言的变体按国际学界的标准则认定为独立的语言,其原因在于所依据的区分语言和方言的标准与国内学界不同。《世界民族语言志》的导论部分提出以下区分“语言”和“方言”的标准:
1.两种语言变体的说话人如果不需要学习另一种话,靠自己母语的知识就可以互相理解通常为同一种语言的两个方言。
2.如果不同变体口语的通话程度较低,但是由于有共同的书面文献,或因有可以互相理解的中心方言而具有民族语言身份认同,还是可以看作一种语言的不同方言。
3.不同变体之间的通话程度即使很高,但是存在明确的不同民族语言身份的认同,则应视为不同的语言。
按此标准,语言可懂度是必要条件,语言认同是充分条件,即民族语言身份认同是比语言可懂度更重要的语言身份识别标准和条件。

这样的标准可以适用于中国某些民族语言和方言的情况。如上述标准1适于内部方言差异小的语言;标准2适于汉语、藏语这类方言口语差别大,但是有共同书面语的语言;标准3适于阿尔泰语系这类语言可懂度高,但是缺少民族语言身份认同的语言。然而按此标准,像苗语、彝语等既没有共同的书面语,也没有中心方言,且语言可懂度极低的众多汉藏语系语言,仅有共同的民族身份,以及语言的历史渊源关系,其不同的地区变体就不是同一种语言的方言,而是不同的语言。可以说,国外学界确认的中国语言数量极大地多于中国学界的根本原因,即在于此。
中国汉藏语系诸语族语言的方言差别一般都比较大,其方言土语之间的可懂度很低,基本不能通话。根据方言内部的差异程度,差异大的方言分次方言和土语两个层次,差异小的方言只分土语。有学者认为,苗语和彝语是汉藏语系方言可懂度最低的语言,也是《世界民族语言志》分立出独立语言最多的两种民族语言。下页表4列举了中国学界对苗语方言土语的分类系统[主要采用《中国少数民族语言简志》(2009)和《中国语言地图集》(2012)的数据],及其与《世界民族语言志》分类系统的对应情况。

彝语可分6个大的方言区,其中东南方言内部的差异最大,孙宏开先生多次发文(如孙宏开2017)质疑其独立语言身份的诸多彝语变体即分布于此方言。该彝语方言内的阿细(Axi)、撒尼(Sani)、阿哲(Azhe)、阿吾(Awu)、濮拉(Pula)、大黑彝、小黑彝等支系相互通不了话(陈康2010)。下页表5是彝语较复杂的南部和东南部方言与《世界民族语言志》分类系统的对应情况。
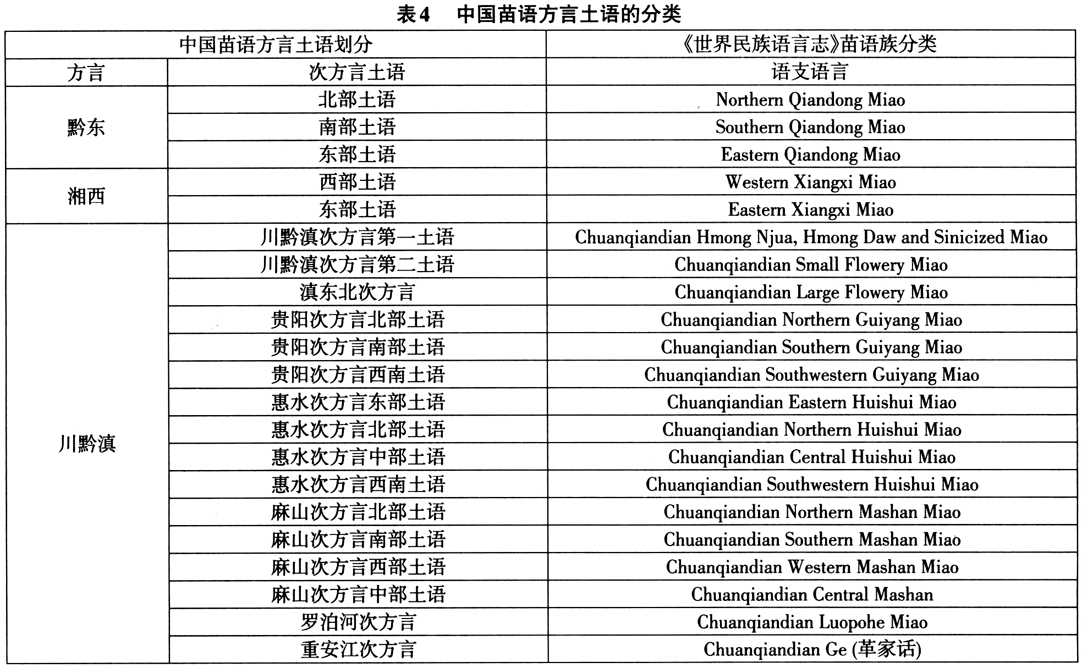
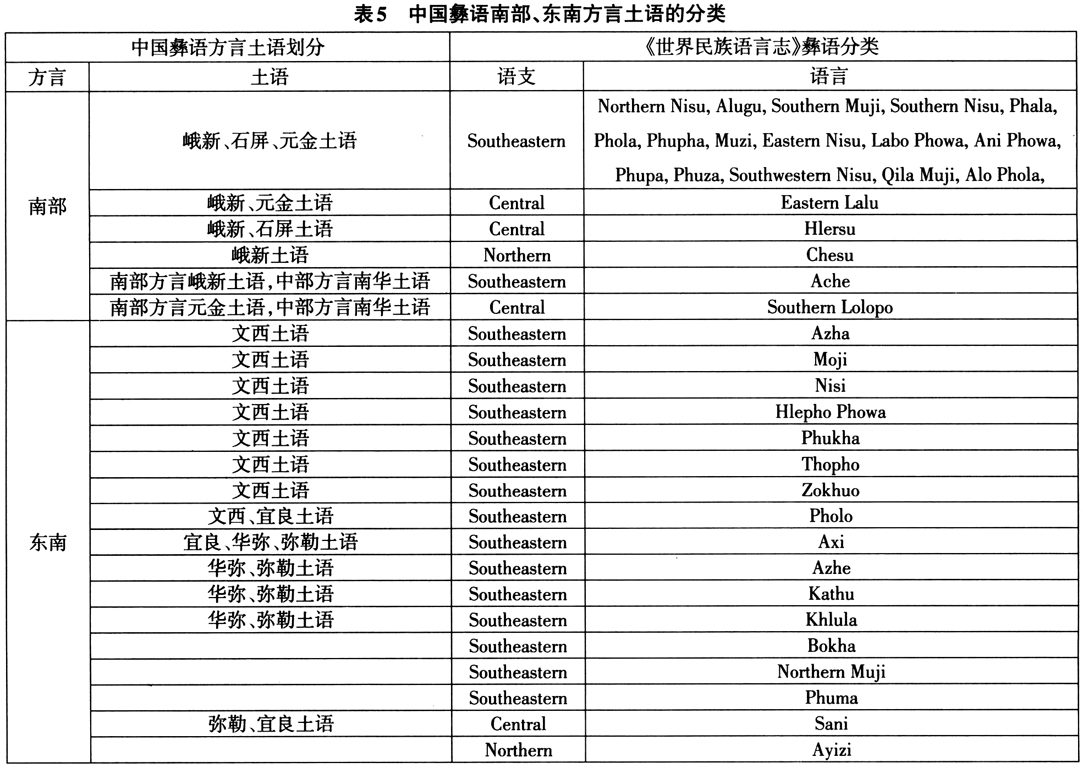
语言和方言可懂度很大程度在于词汇的相似度(lexical similarity),“从技术上讲,能够相互通解的言语形式称为方言;不能互相通解的言语形式则称为语言”(法兰克·布莱尔2006)。确定语言相似程度的方法有多种,但语言相似程度通常是在比较标准词表所收录词汇的对应情况之后,用语音相近的词所占词表词汇总数的百分比来表示。如果词汇比较的结果显示,两种言语变体之间的相似程度高于60%,就必须进行方言可懂度测试。假如词汇比较结果显示可懂度低于80%,那么这两种言语变体就可视为“不相似方言”或“不同语言”。如果方言可懂度测试结果显示,两种言语变体的可懂度很高(超过80%),那么这两种言语变体就可视为相似方言。词汇相似度与方言可懂度的交叉关系见表6。

以藏缅语族的白语方言为例。白语分中部方言(以剑川话为语音标准)、南部方言(以大理话为语音标准)、北部方言(以碧江话为语音标准),诸方言之下又各分2个土语。有学者认为中部和南部方言比较接近,相互交谈能听懂一半左右,中部、南部方言与北部方言差别较大,尤其是南部和北部方言差别更甚(徐琳,赵衍荪1984)。艾磊(2004)用词汇相似性比较和可懂度测试的方法分析了白语的方言差异,结果如表7。

因诸白语方言的词汇相似度大于60%,即可进一步进行方言可懂度测试。白语方言可懂度测试结果如表8。
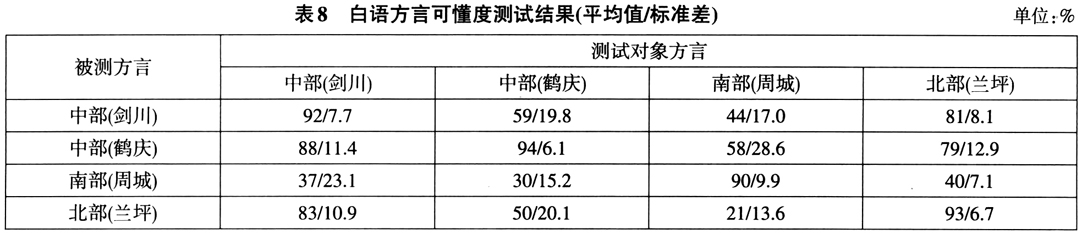
白语诸方言之间词汇相似度可以满足确定为同一语言不同方言的条件,但是主观听辨的可懂度却相差很大。比如只有中部方言(剑川话、鹤庆话)与北部方言(兰坪话)之间的可懂度超过或接近80%,南部方言(周城话)与中部、北部方言之间的可懂度都很低(21%-58%),且从标准差值可见被测试对象可懂度的个体差异都较大,甚至同属中部方言,鹤庆人听剑川话也有一定困难(可懂度为59%)。据此,《世界民族语言志》(2017)将白语方言认定为中部白语、南部白语和北部白语等三种独立的语言。
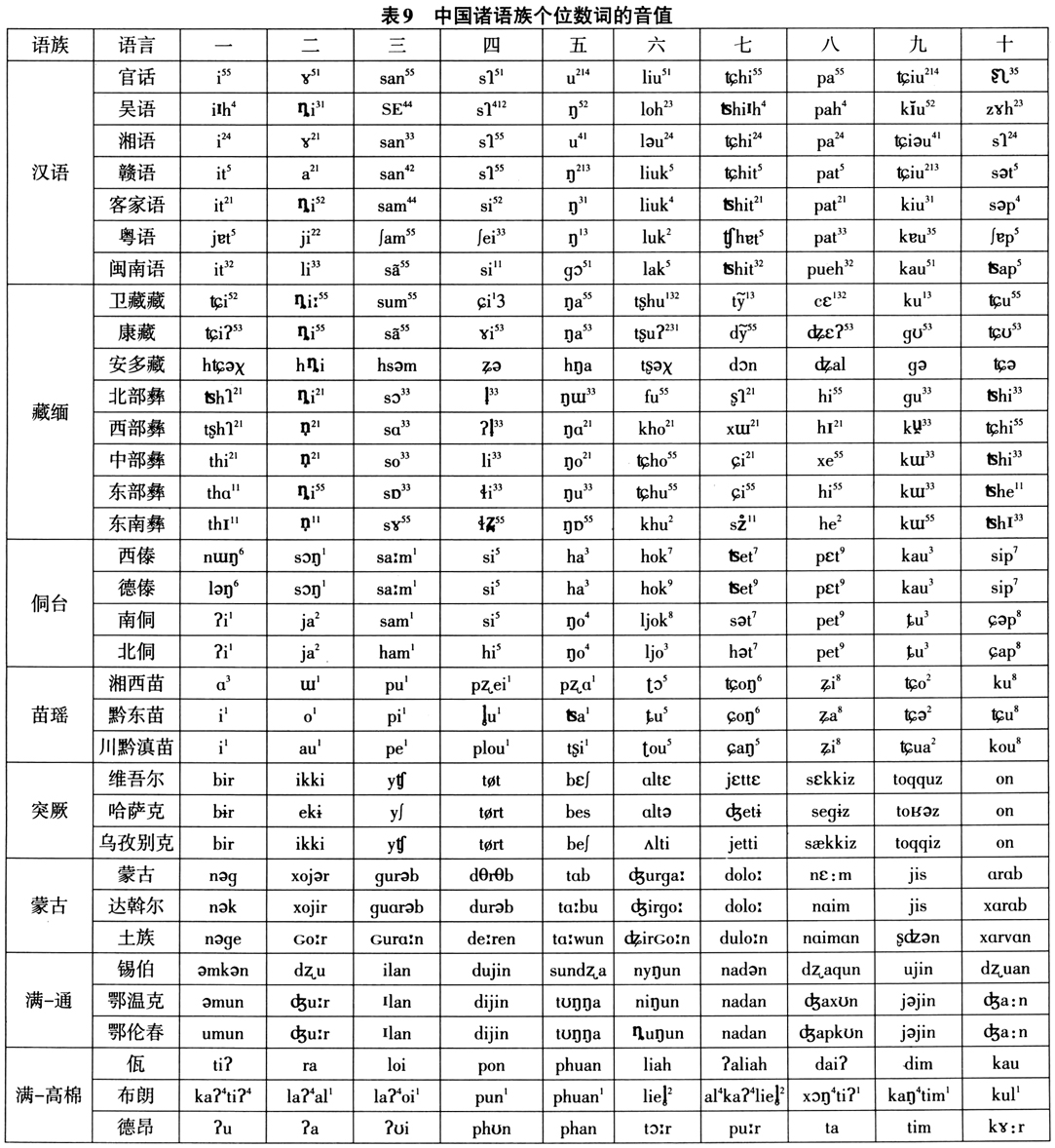
为进一步说明中国语言方言词汇语音形式的相似度,表9列举了汉藏语系汉语、藏缅、侗台、苗瑶诸语族,阿尔泰语系突厥、蒙古、满-通古斯诸语族和南亚语系孟-高棉语族等中国主要语族代表性语言或方言数词1-10的语音形式,这些数词可以100%地确定为相关方言甚至语言之间的同源词(除侗台语的数词是汉语借词外),但是由于词汇相似度并不取决于词语是否同源,因此不同语族的语言和方言词汇语音形式相似程度的差别可能甚大。如表中词语的实际音值可以非常直观地显示,中国北方阿尔泰语系突厥、蒙古、满-通古斯语族语言之间的词汇相似度,要明显地高于南方汉藏语系汉语、藏缅、侗台、苗瑶语族语言的方言之间,而其中苗瑶语族苗语的方言差异又是最大的。因此说明如果采用词汇相似度以及基于词汇相似度的通话可懂度标准识别语言,中国南方诸语族语言的数量和层次将极大地增加。
语言首先是人们重要的社会交际工具,所以一般来说用是否可以交际或通话的标准来区分语言和方言确实体现了语言基本的社会功能;同时语言也有使用群体身份相互认同或不认同的社会符号功能,所以即使可以交际或通话的语言变体,使用群体互相不认同也不能视为同一种语言。这种可以通话却互不认同同一语言的现象看似离奇,但在世界各地却十分普遍,不胜枚举。然而在技术上,语言可懂度和语言认同度标准的可操作性却并不高,这是《世界民族语言志》语言识别结果时常会受到诟病的主要问题。
再看中国国内民族语言学界区分语言和方言的标准,也并非与国外的标准截然不同。比如其一,国内注重语言使用者“民族身份”对语言身份识别的作用,在某种意义上与说话人对“民族语言群体认同”的标准有不谋而合之处。因为根据中国“民族”的定义,共同的语言是构成民族的基本要素和条件之一,反之由于民族是语言使用的主体,语言识别也要参考语言群体的民族身份,也即中国的“民族群体”与“民族语言群体”有相当程度的交集。
再如其二,国内学者强调的“同源词”对语言识别的作用,也与方言通话可懂度所基于的“词汇相似度”标准有一定的联系。特别是当理想的“同源词”不仅语音音类对应整齐,而且音值对应也相似时,“同源词”对语言识别的作用会十分明显,例如表9突厥语族的维吾尔语、哈萨克语和乌孜别克语数词的音值高度相似,如出一辙。不过从理论上说,“词汇相似度”是纯共时的语言范畴,与属语言历时范畴的“同源词”没有必然联系。事实上,发生时间晚的词汇借用对“词汇相似度”的贡献一般要比发生时间早的“同源词”更大,例如表9侗台语族的傣语和侗语数词的音值之所以相似度很高,就是因为它们都是汉语的借词(傣语的“一”“五”除外),而真正的侗台语母语数词的语音形式早已演变得面目全非或消失殆尽了。
①《不列颠百科全书》(Encyclopedia Britannica):汉藏诸语(Sino-Tibetan languages)、阿尔泰诸语(Altaic languages)、苗瑶语言(Hmong-Mien languages),https://www.britannica.com/topic-browse/Society/Languages。
②维基百科(Wikipedia,the free encyclopedia):语系(Language family),https://en.wikipedia.org/wiki/Language_family。
参考文献:
[1]《中国大百科全书》(第二版)编辑部 2011 《中国大百科全书》(第二版),北京:中国大百科全书出版社.
[2]《中国大百科全书》编辑委员会 1988 《中国大百科全书》,北京:中国大百科全书出版社.
[3]《中国少数民族语言简志丛书》编委会,《中国少数民族语言简志丛书》修订本编委会 2009 《中国少数民族语言简志丛书》(修订本),北京:民族出版社.
[4]艾磊(Bryan Allen) 2004 《白语方言研究》,张霞译,昆明:云南民族出版社.
[5]陈康 2010 《彝语方言研究》,北京:中央民族大学出版社.
[6]陈士林等 1985 《彝语简志》,北京:民族出版社.
[7]法兰克·布莱尔 2006 《双语调查精义》,卢岱译,北京:民族出版社.
[8]黄行 2009 《语言识别与语言群体认同》,《民族翻译》第2期.
[9]金理新 2012 《汉藏语系核心词》,北京:民族出版社.
[10]李方桂 1973/1980 《中国的语言和方言》,梁敏译,《民族译丛》第1期.
[11]孙宏开 1998 《中国新发现语言研究丛书》,北京:民族出版社/北京:中央民族大学出版社/上海:上海远东出版社.
[12]孙宏开 2017 《全球语言知多少?——有关语言识别和语言与方言界限的讨论》,载北京语言大学语言资源高精尖创新中心“‘一带一路’语言资源与智能国际学术研讨会”会议论文,7月15-16日.
[13]孙宏开,胡增益,黄行 2007 《中国的语言》,北京:商务印书馆.
[14]夏征农,陈至立 2009 《辞海》(第六版),上海:上海辞书出版社.
[15]徐琳,赵衍荪 2009 《白语简志》,北京:民族出版社.
[16]中国社会科学院,香港城市大学 2012 《中国语言地图集》(第二版),北京:商务印书馆.
[17]Lewis,M.Paul,Gary F.Simons,and Charles D.Fennig(eds.).2009.Ethnologue:Languages of the World.16th edition.Dallas:SIL International.
 切换用户
切换用户 收藏
收藏


 纠错
纠错
 京公网安备11010202010100号
京公网安备11010202010100号



